Google搜索引擎如何爬行和索引
zx 2021-08-10
进行网站优化,必须首先了解搜索引擎是如何工作的,就像你想要出版一部伟大的小说,要首先学习如何写作一样。
虽说无数猴子在无数打字机上持续不断的随机打字,那么最终在某个时候总能写出一些有用的东西(无限猴子定理),但是如果我们在做任务前能首先抓住任务的核心要素,那么我们可以节省很多精力。
所以我们在进行网站的搜索引擎优化前必须充分理解搜索引擎是如何工作的。
虽然我们主要研究Organic Search(关键词自然搜索),但我们还是有必要先简要讨论一下关于搜索引擎的一个重要事实。
1.付费搜索结果
不论是Google,还是Bing,或是其他主流搜索引擎,提供自然搜索结果都不在他们的商业意图内。
也就是说,虽然自然搜索结果是最终实际的搜索结果,但他并没能给Google带来直接的收益。
如果没有自然搜索结果的存在,Google的付费搜索结果就没有那么重要,那么吸引眼球了,付费点击量也会下降。
基本上,Google和Bing(以及其他的搜索引擎)都可以说是广告引擎,它们会碰巧把用户引导到他们的自然搜索结果中。因此,我们网站优化的最终目的是自然搜索结果排名。
2.自然搜索结果为何如此重要
自然搜索的重要性在于:搜索引擎搜索结果的布局在变化。
搜索引擎存在一些扩展功能,比如:Knowledge Panels(知识面板),Featured Snippets(精选摘要)等;自然搜索有一定相当可观的点击率。
Google在有商业意图的查询中推出了第四种付费搜索结果,又推出了不用离开Google.com页面直接在搜索结果页面就能获取查询问题答案的特色功能……这些功能的推出都是因为自然搜索结果的存在。
不管你看到Google有什么变化,请记住重要的一点:不要只看它会对目前会产生什么影响,而是要看它有什么长远影响。
既然我们已经了解了为什么Google会提供自然搜索结果,那我们来看看它是如何运作的。为了弄明白这一点,我们需要研究:爬行和索引;排序算法;机器学习;用户搜索意图等。本文着重于索引,下面让我们来一探究竟……
3.索引
索引是我们研究搜索引擎问题的起点。
对于那些不怎么了解搜索引擎的人,索引简单点来讲就是指将网页内容添加到Google中。
当你在网站上创建一个新的页面时,有许多方法可以让网页被索引。
让网页被索引的最简单方法是什么都不做。
Google有爬虫跟踪链接,因此,如果你已经把站点提交给Google索引,并且新内容是链接到你的站点的,Google最终都会发现它并将它添加到索引库中。后面我们再详细介绍。
如果你想让Googlebot(谷歌蜘蛛)更快地进入你的网站页面,该怎么办呢?
有一点非常重要:你要有比较时新的内容,你要让Google知道你对一个网页进行了比较重要的修改。
这也是当我们优化了网站一个很重要的页面,或是调整了网页标题和描述来提升点击率,或是为了探索网页何时被搜索引擎选中并出现在搜索结果页面中时,让谷歌蜘蛛更快索引网站的一个很重要的原因。
想让Googlebot(谷歌蜘蛛)更快地爬行和索引网页,还可以采用以下几种方法:
1)XML Sitemaps
基本上,XML Sitemaps是通过Google Search Console(谷歌站长工具)提交给Google的站点地图。
XML站点地图为搜索引擎提供了站点上所有页面的列表,以及其他的一些附加细节比如XML Sitemaps最后一次的修改。
这种方法绝对值得推荐!
但是,如果你需要搜索引擎立即爬行和索引页面呢?这一方法又并不那么可靠了。
2)Google抓取工具
在Google Search Console中,你可以使用Fetch as Google(谷歌抓取工具)。
在左边的导航栏中,只需点击Crawl(抓取)> Fetch as Google(谷歌抓取工具)。
输入你想要索引的URL,然后单击Fetch(抓取)。
在获取你的URL之后,你将会看到“请求索引”的选项。
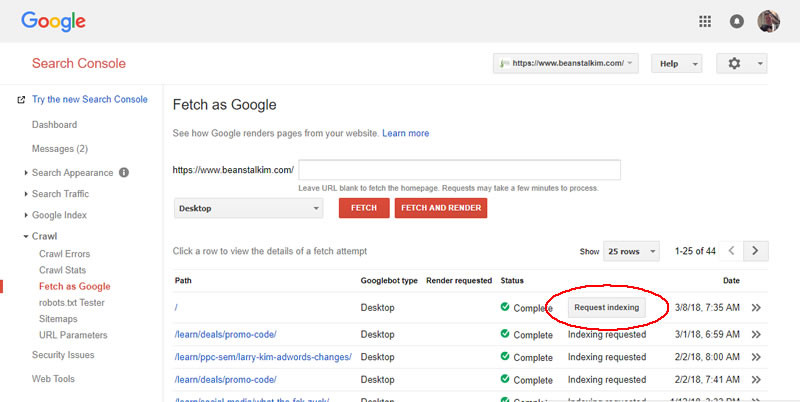
点击这一选项按钮。
通常在几秒钟到几分钟内,你可以在Google中搜索新提交的内容或URL,并发现更改的新内容已经被收录。
3)向Google提交URL
如果懒得去登录Google Search Console,或者想让网站新内容在第三方网站上快速更新?那就直接Google一下吧。
只需简单的在Google搜索框里输入【Submit URL to Google】,你将会得到一个URL字段的提交框。
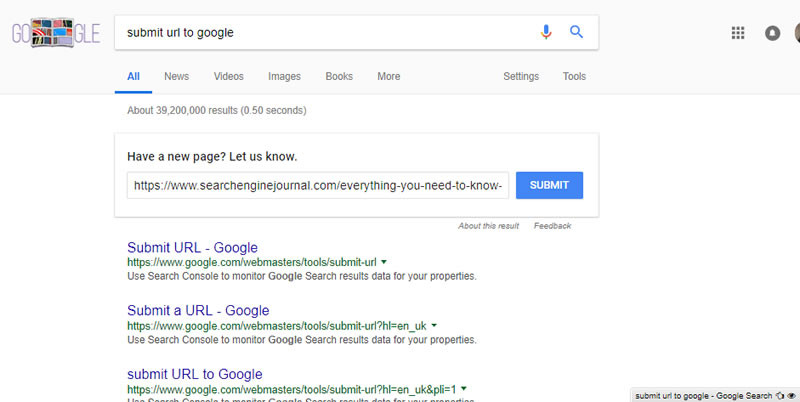
这就像是通过搜索控制台一样快速地提交网页。
在Bing中,你同样可以这样操做。
4)Google Plus(Google+, G+)
Google+是一个SNS社交网站,可以通过Google帐户登录,在这个社交网站上可以和不同兴趣的好友分享好玩的东西。于2011年6月28日亮相,现在仍处于测试阶段。
将一个新的URL发布到Google+,几秒钟内你就会看到它已经被索引。
Google必须通过抓取URL来获取图片、描述等信息,通过读取这些信息来判断网页是否已经被索引。
这可能是让Google索引内容排名第二快的方法。至于最快的方法,还有待研究……
5)在Google上托管网站内容
Google爬行站点、索引网页需要一个时间过程。其中一种方法是直接将网站内容托管给Google。
托管内容有几种不同的方式,但是我们大多数人没有采用这些技术和方法,而且Google也没有向我们推荐这些方法。
我们允许Google通过XML feeds文件, APIs接口等可以直接访问网站内容,提取信息,其实就已经在把网站托管给Google了。
Firebase,Google的移动应用平台,在不需要抓取任何信息的情况下就可以直接访问应用程序的内容。
这是未来的一个趋势:让Google轻松快速的索引网站内容,从而让搜索引擎可以更多的在技术层面上为网站提供服务。
4.爬行预算
我们讨论索引,不能不说爬行预算。
爬行预算可以理解为搜索引擎蜘蛛花在一个网站上抓取页面的总的时间上限。
预算的份额是受多方面因素影响的,有两点是十分重要的:
1)网站服务器反应速度有多快
就是说在不影响用户访问体验的情况下谷歌蜘蛛能抓取网站网页的最快速度,搜索引擎蜘蛛不会为了抓取更多页面,把网站服务器拖垮,所以对某个网站都会设定一个网页抓取速度的上限,也就是服务器能承受的上限,在这个速度限制内,搜索引擎蜘蛛抓取不会拖慢服务器、影响用户访问。抓取速度限制会影响搜索引擎能够抓取的网页数。服务器反应速度下降,抓取速度限制跟着下降,抓取减慢,甚至停止抓取。
2)网站的重要性(可以理解为网站的权重)
如果你在运营一个大型的新闻站点,持续不断的更新搜索用户想要了解的信息,那么你的站点被抓取和索引的频率就会很高(这一点我敢保证!)。
如果你运营一个小型站点,有几十个链接,在这种情况下,你的网站就不会被Google认为是重要的(你可能在某个领域很重要,但当涉及到爬行预算的话就显得不那么重要了),那么爬行预算就会很低。
小网站页面数少,即使网站权重再低,服务器再慢,每天搜索引擎蜘蛛抓取的再少,通常至少也能抓个几百页,十几天怎么也会把全站抓取一遍了。